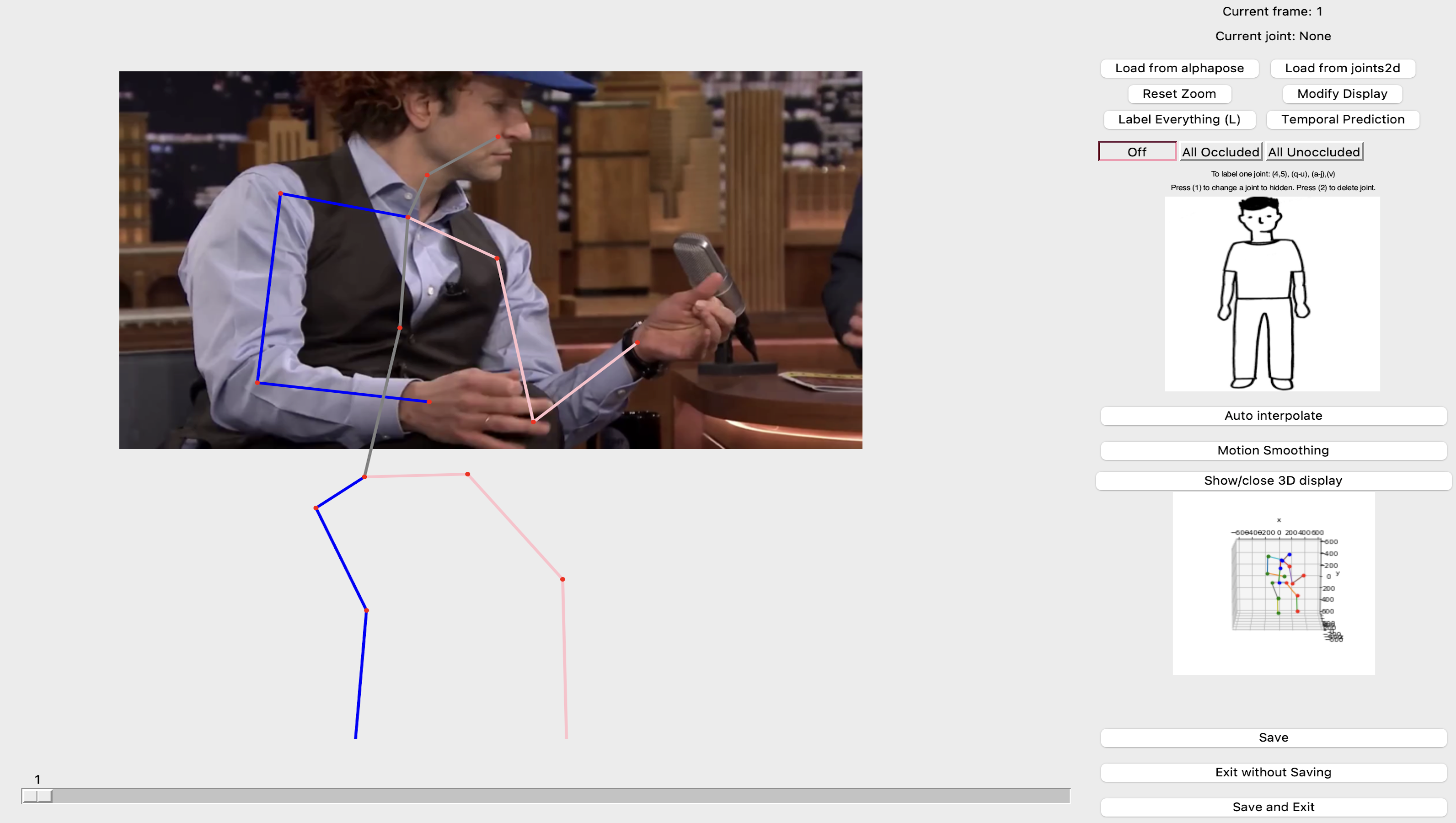
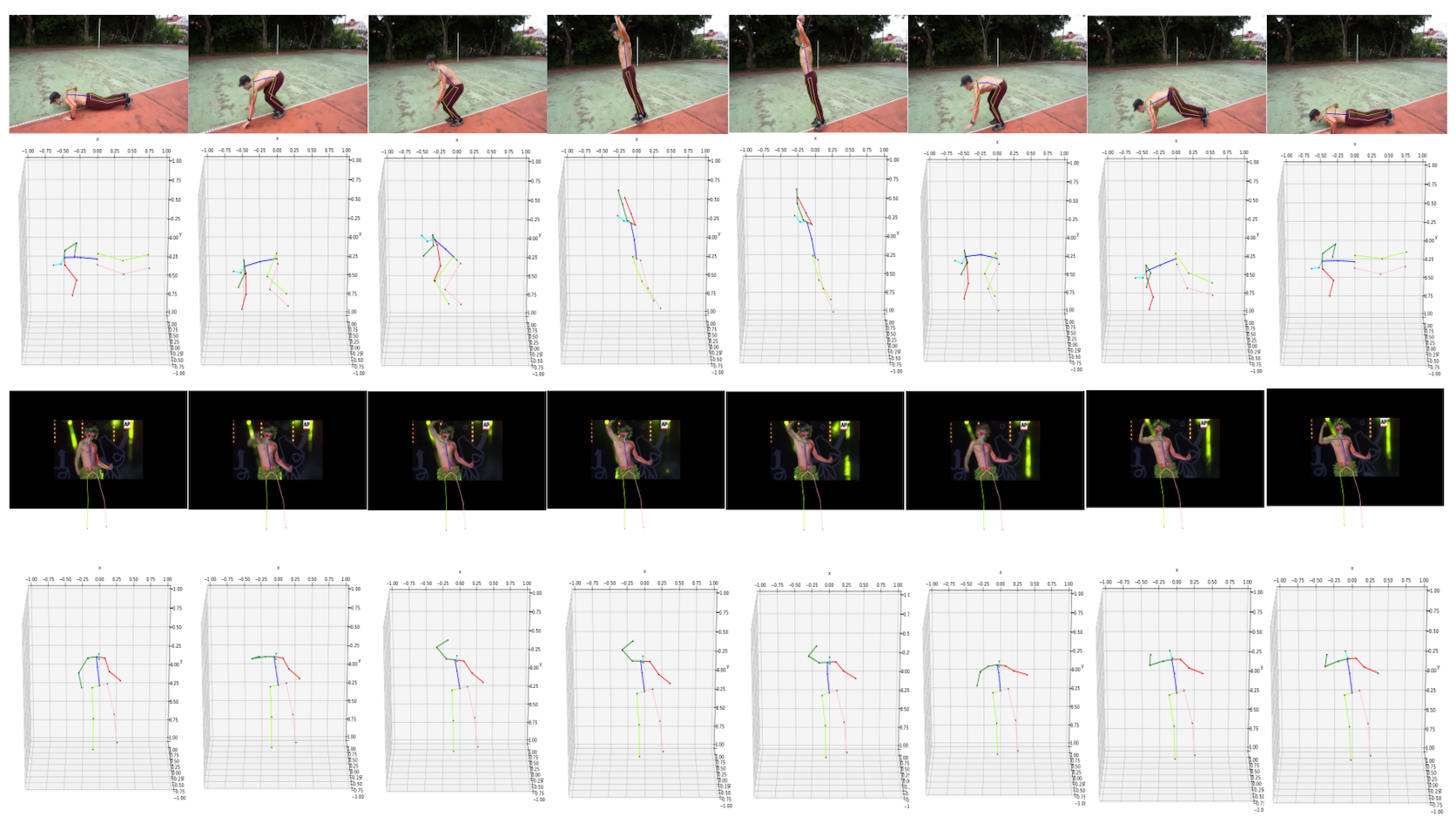
Others
Training Configuration
For training the global alignment network, we perform data augmentation by sampling camera views from a 3-frequency subdivision icosahedron. This gives us 92 additional training samples per example. Since there are 400 examples in HAA4D that are provided with globally aligned skeletons, with the help of data augmentation, we have 36,800 examples of training our global alignment network. We split all the data into training and validated with a ratio of 0.8 under two settings: cross-views and cross-actions. We select 73 views on the icosahedron sphere for cross-views and test the rest 19 views to ensure that our network generates predictions decently while encountering unseen views. We also trained our network on cross-views, i.e., 32 out of the 40 classes, to secure that the model is used to generalize different actions. Here are our training environment and configurations in more details:
- GPU: GeForce GTX TITAN X and GeForce GTX 1080 Ti
- Epochs: 300
- Batch size: 64
- Optimizer: Adam (starting learning rate: 1e-4, weight decay rate: 1e-6)
- Loss weight: 10:1 (rotation loss : reconstruction loss)
Limitations
- Our dataset contains only a few samples per class, which is intended for enhancing its scalability and extension (e.g. 1 for train and 1 for test, see our 5-way 1-shot experiments in main paper), as unlike the 2D counterparts, HAA4D's 3D+T skeletons have more degree of freedom making meaningful data augmentation easy for training on large datasets. In our case, we sample the 3D skeletons from different viewpoints and rotate the skeletons accordingly. We can also use mirroring or combining skeleton samples in the same class to introduce more variation to the dataset. Unlike 2D skeletons that can only have one rotation parameter, the properties of 3D skeletons help better perform data augmentation without breaking the original skeleton structure.
- Our few-shot skeleton-based action recognition architecture currently supports only single-person actions. To accommodate actions involving more than one person, we can use a similar technique as ST-GCN, which utilizes the two skeletons with the highest confidence score in the sequences. For actions that have only one subject, we assume them to be all zeros. With this, we can modify our architecture so that instead of having the shape of (n_ways, n_shots, n_segments, n_encodings) for explicit skeletons encodings, we add one additional dimension so that the skeletons are in the shape of (n_ways, n_shots, 2, n_segments, n_encodings). We then calculate the distance, respectively. Since there are four skeleton sequences, assuming q_s1, q_s2, s_s1, and s_s2 all with the shape of (1, n_segments, n_encodings), we use the minimum distance between the possible combination {d(q_s1,s_s1) + d(q_s2,s_s2), d(q_s1,s_s2) + d(q_s2,s_s1)}. Therefore, we can make this adjustment for multi-person interaction, and the rest of the architecture can remain unchanged.
Contact
Please email Mu-Ruei Tseng (morris88826@gmail.com) for any questions.