More about HKUST
CODA: Facilitating Big Data Applications via Network Optimization
Scale matters. In an unprecedented era of big data, and with the rapid rise of cloud computing, scale-out big data applications running on large clusters are becoming the norm. However, as cluster and data scale grow, so does the execution time; discovering the potential of scaling big data applications requires developing novel techniques to keep the execution time manageable.
In particular, communication is crucial for analytics at scale. Many of the big data applications are communication-intensive. Given the huge amount of data that needs to be synchronized among tens to thousands of workers, the communication stage can be the bottleneck that greatly affects the execution time. As a result, network system design has embraced new challenges and opportunities.

The data center system platform in SING Lab HKUST
After joining HKUST in 2012, Prof. Kai Chen has devoted himself to network systems design and implementation. For Kai and his SING Lab, one major theme of research is to provide efficient and intelligent networking support for big data and cloud computing. For this purpose, his group has implemented a 100+ node data center platform. As one of the many cutting-edge research projects done on top of the platform, the CODA system serves as a necessary and natural step towards practical network optimization for data-parallel applications.
Traditional approaches toward improving network-level metrics are often misaligned with the goals of data-parallel applications. Although a data-parallel application treats all the flows in each communication stage (e.g., shuffle or broadcast) as a whole, the network treats each flow independently. To bridge this gap, the Coflow abstraction was proposed in 2012 to enable the network to realign its objectives with that of the applications. Since then, people have been working hard to make it practical. Throughout all their efforts, one requirement remained constant: all distributed data-parallel applications had to be modified to use the same Coflow API. Unfortunately, this is hard to do, because of the sheer number of computing frameworks available today.
CODA makes a first attempt at addressing this problem head on. The intuition is simple: if we can automatically identify coflows from the network, applications need not be modified. There are at least two key challenges in achieving this goal. The first one is classifying coflows. Note that the identification must be application-transparent, i.e., involve no application modification. Unfortunately, unlike traditional traffic classification, coflows cannot be identified using five-tuples. The second challenge is avoiding the impact of misclassification, because even the best classifier will sometimes be wrong. To that end, the scheduling should be error-tolerant, i.e., it must be able to schedule coflows even when some flows have been misclassified.
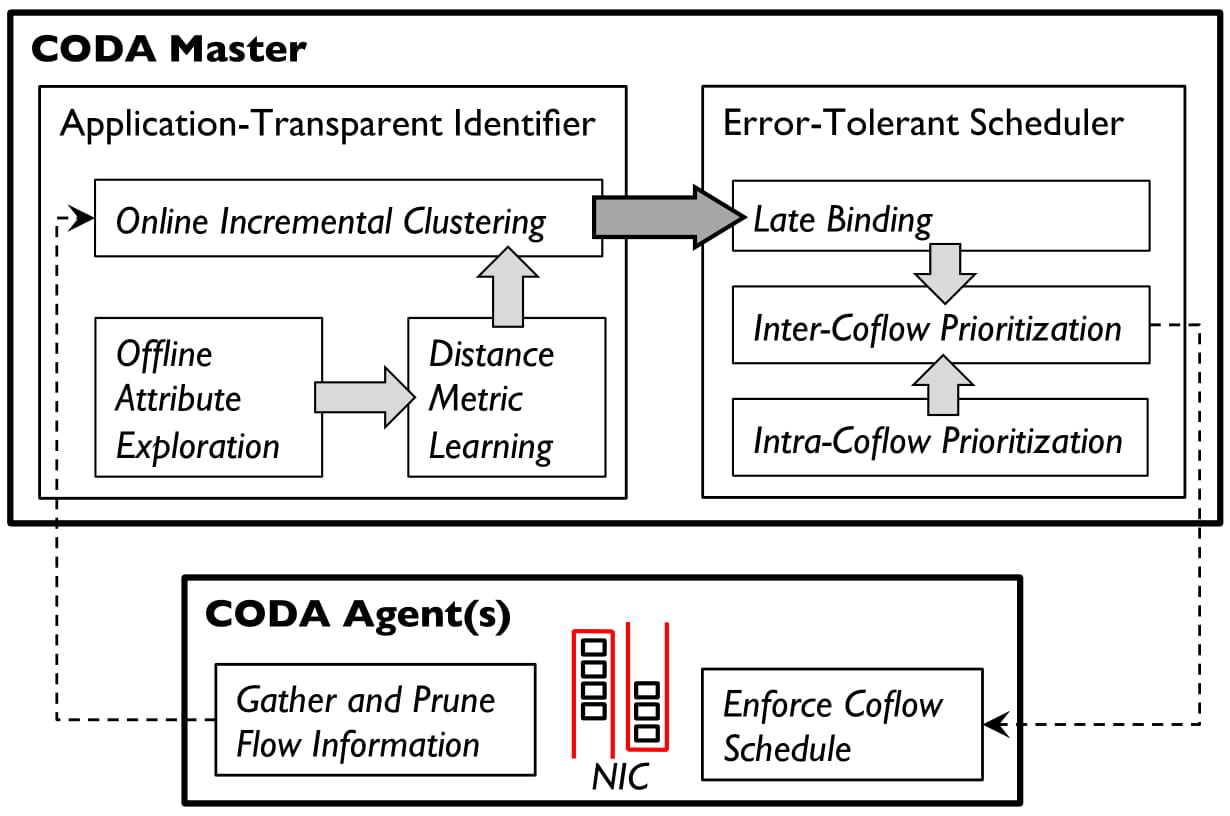
CODA Architecture
CODA is a joint design to address these two challenges. For application-transparent coflow classification, CODA leverages domain-specific insights and simple machine learning techniques to capture the logical relationship between multiple flows. Furthermore, an incremental clustering algorithm is developed to provide fast identification with high accuracy. For error-tolerant coflow scheduling, a key design of late binding is proposed. By delaying the assignment of flows to particular coflows, CODA always errs on the side of caution and effectively minimizes the impact of identification errors.
Testbed experiments and large-scale simulations with realistic production workloads showed that CODA can identify coflows with more than 90% accuracy and its scheduler is robust to inaccuracies. Overall, CODA's performance is comparable to that of solutions requiring application-level modifications, and significantly outperforms flow-based solutions.
CODA appeared in SIGCOMM 2016, the flagship conference of ACM on the applications, technologies, architectures, and protocols for computer communication, widely recognized as one of the most challenging CS conferences. This is the first time for SIGCOMM to have home-grown papers from Hong Kong universities.
Navigation

Navigation

 Facebook
Facebook LinkedIn
LinkedIn Instagram
Instagram YouTube
YouTube Contact Us
Contact Us