More about HKUST
Learning to Synthesize Images
Given a semantic layout of a scene, can an artificial system synthesize an image that depicts this scene and looks like a photograph? The research by Prof. Qifeng Chen shows that an AI program can successfully render fictional novel scenes based on human input. As shown in the first figure, the deep learning model called the cascaded refinement network is able to generate photographic images based on semantic layouts.
Learning-based image synthesis is connected to central problems in computer graphics and artificial intelligence. First, consider the problem of photorealism in computer graphics. A system that synthesizes photorealistic images from semantic layouts would in effect function as a kind of rendering engine that bypasses the laborious specification of detailed three-dimensional geometry and surface reflectance distributions, and avoids computationally intensive light transport simulation. Another source of motivation is the role of mental imagery and simulation in human cognition. Mental imagery is believed to play an important role in planning and decision making. The level of detail and completeness of mental imagery is a matter of debate, but its role in human intelligence suggests that the ability to synthesize photorealistic images may support the development of artificial intelligent systems.

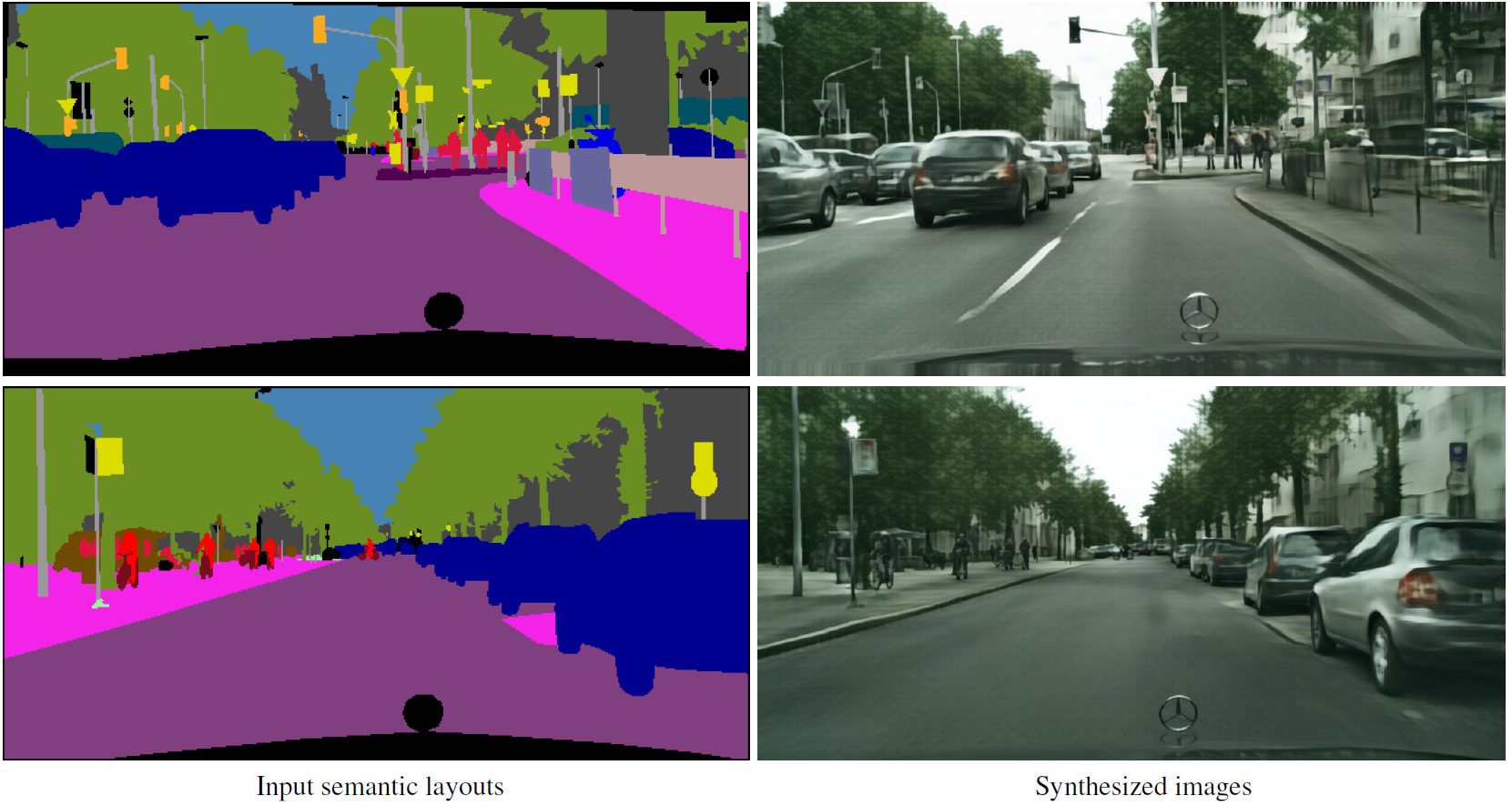
More recently, the research of Qifeng studies a semi-parametric approach to photographic image synthesis from semantic layouts. The second figure shows the image synthesis results by the semi-parametric approach. This approach combines the complementary strengths of parametric and nonparametric techniques. The nonparametric component is a memory bank of image segments constructed from a training set of images. Given a novel semantic layout at test time, the memory bank is used to retrieve photographic references that are provided as source material to a deep network. The synthesis is performed by a deep network that draws on the provided photographic material.
Navigation

Navigation

 Facebook
Facebook LinkedIn
LinkedIn Instagram
Instagram YouTube
YouTube Contact Us
Contact Us