More about HKUST
MLaaS in the Wild: Workload Analysis and Scheduling in Large-Scale Heterogeneous GPU Clusters
Driven by recent algorithmic innovations and the availability of massive datasets, machine learning (ML) has achieved remarkable performance breakthroughs in a multitude of real applications such as language processing, image classification, speech recognition, and recommendation. Today's production clusters funnel large volumes of data through ML pipelines. To accelerate ML workloads at scale, tech companies are building fast parallel computing infrastructures with a large fleet of GPU devices, often shared by multiple users for improved utilization and reduced costs. These large GPU clusters run all kinds of ML workloads (e.g., training and inference), providing infrastructure support for ML-as-a-Service (MLaaS) cloud.
Prof. Wei Wang has been collaborating with Alibaba Cloud in optimizing the scheduling of massive ML workloads in large GPU clusters. Working with Alibaba researchers, Prof. Wei Wang's team recently conducted an extensive characterization of a two-month workload trace collected from a production cluster with 6,742 GPUs in Alibaba PAI (Platform for Artificial Intelligence). The workloads are a mix of training and inference jobs submitted by over 1,300 users, covering a wide variety of ML algorithms including convolutional and recurrent neural networks (RNNs and CNNs), transformer-based language models, GNNs-based (graph neural network) recommendation models, and reinforcement learning. These jobs run in multiple ML frameworks, have different scheduling requirements like GPU locality and gang scheduling, and demand variable resources in a large range spanning orders of magnitude. GPU machines are also heterogeneous in terms of hardware (e.g., V100, P100, T4) and resource configurations (e.g., GPUs, CPUs, and memory size).
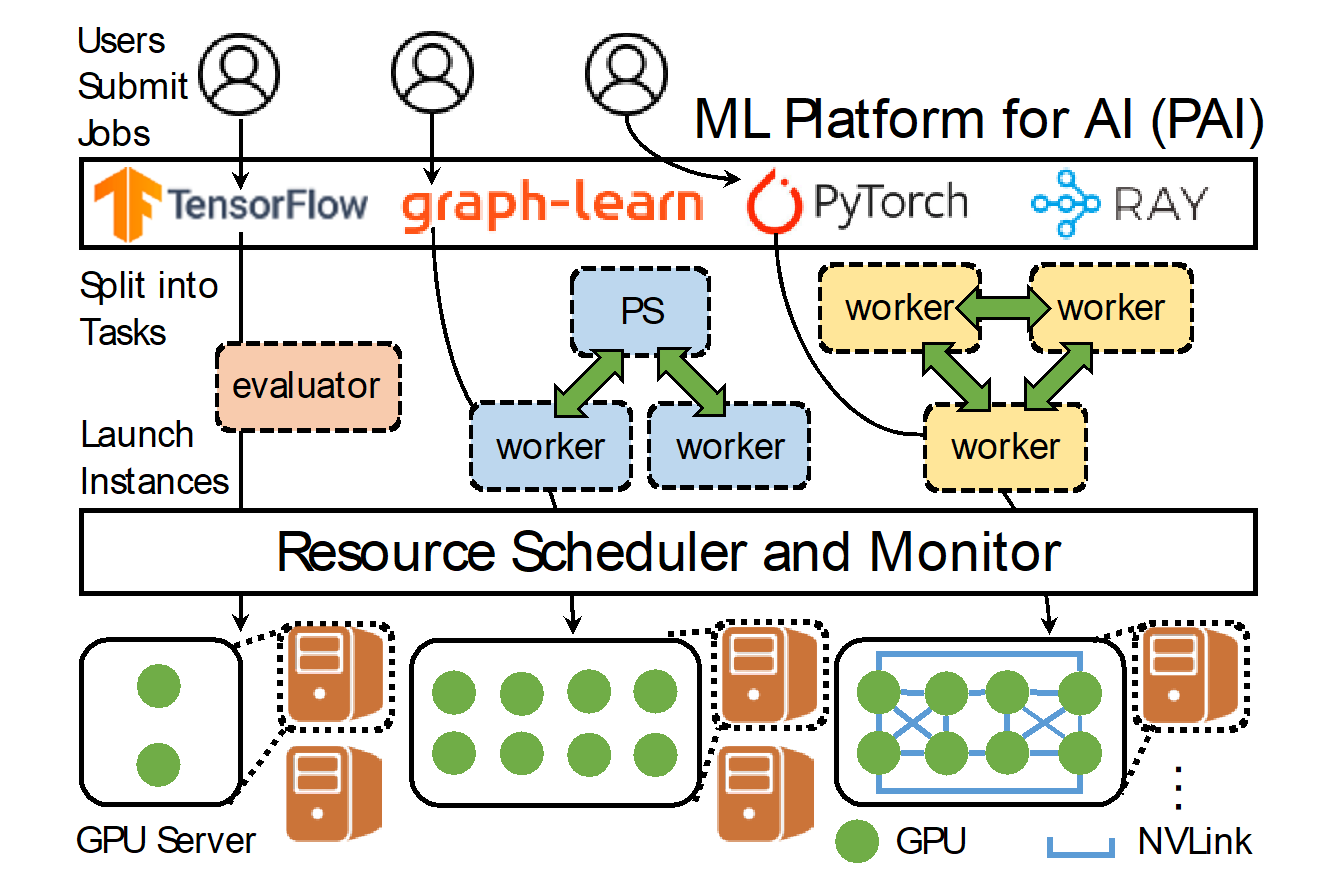
Architecture overview of Alibaba's ML Platform for AI (PAI)
The large heterogeneity of ML workloads and GPU machines raises a number of challenges in resource management and scheduling, making it difficult to achieve high utilization and fast task completion. Notably, the majority of tasks have gang-scheduled instances and are executed recurrently. Most of them are small, requesting less than one GPU per instance, whereas a small number of business-critical tasks demand high-end GPUs interconnected by NVLinks in one machine. For those low-GPU tasks, CPU is often the bottleneck, which is used for data pre-processing and simulation. To better schedule ML workloads in PAI clusters, the cluster scheduler enables GPU sharing and employs a reserving-and-packing policy that differentiates the high-GPU tasks from the low-GPU ones. The researchers also identified a few challenges that remain open to address, including load imbalance in heterogeneous machines and the potential CPU bottleneck. The researchers have released the collected trace for public access to facilitate further investigations on those open challenges. This research has been accepted to USENIX NSDI 2022.
Navigation

Navigation

 Facebook
Facebook LinkedIn
LinkedIn Instagram
Instagram YouTube
YouTube Contact Us
Contact Us